文本挖掘与文本分类的概念
文本挖掘:是指从大量的文本数据中抽取事先未知的、可理解的、最终可用的知识的过程,同时运用这些识更好的组织信息以便将来参考。
搜索和信息检索(IR):存储和文本文档的检索,包括搜索引擎个关键字搜索
文本聚类:使用聚类方法,对词汇、片段、段落或文件进行分组和归类
文本分类:对片段、段落或文件进行分组和归类,在使用数据挖掘分类方法的基础上,经过训练的标记示例模型。
Web挖掘:在互联网上进行数据和文本的挖掘,并特别关注网络的规模和相互的联系。
信息抽取(IE):从非结构化文本中识别与提取有关的事实和关系:从非结构化或半结构化文本中抽取结构化数据的过程。
自然语言处理(NLP):将语言作为一种有意义、有规则的符号系统,从底层解析和理解语言的任务(例如词性的标注);目前的技术方法主要从语法、语义的角度发现语言最本质的结构和所表达的意义。
概念的提取:把单词和短语按语义分成意义相似的组
文本分类项目
文本分类的一般步骤:
(1)预处理:去除文本的噪声信息,例如HTML标签、文本的格式转换、检测句子边界等。
(2)中文分词:使用中文分词器为文本分词,并去除停用词。
(3)构建词向量空间:统计文本词频,生成文本的词向量空间。
(4)权重策略—TF-IDF方法:使用TF-IDF发现特征词,并抽取为反应文档主题的特征。
(5)分类器:使用算法训练分类器。
(6)评价分类结果:分类器的测试结果分析
文本预处理
1.选择处理的文本的范围
2.建立分类文本语料库
中文文本分类语料库下载地址为:点击这里(但我阅读本书的时候,此网址已失效,我找的这个)
3.文本格式转换
Python去除HTML标签,一般使用lxml
2.2.2 中文分词介绍
文本的结构化表示简单分为四大类:词向量空间模型、主题模型、依存句法的树表示、RDF的图表示
jieba分词简单的样例代码:
本项目创建分词后,语料路径为Root\train_corpus_seg.
1)设置字符集,并导入jieba分词包
在实际应用中,为了后续的生成空间模型的方便,这些分词后的文本信息还要转化为文本向量信息并对象化需要引入Scikit-Learn库的Bunch的数据结构:
Scikit-Learn库介绍
向量空间模型
可以从http://www.threedweb.cn/thread-1294-1-1.html下载
(同样,这里网址失效,我使用的是这个)
读取停用词:
权重策略:TD-IDF方法
含义:如果某个词或短语在一篇文章中出现的频率越高,并且在其他文章中很少出现,则认为此词或者短语具有很好的类别区分能力,适合用来分类。
词频(Term Frequency,TF)指的是某一个给定的词语在该文件中出现的频率。这个数字是对词数(Term Count)的归一化,以防止它偏向长的文件。对于在某一特定文件里的词语来说,它的重要性可以表示为:
其中,分子是该词在文件中出现的次数,分母是文件中所有字词的出现次数之和:
逆向文件频率(Inverse Document Frequency,IDF)是一个词语普遍重要性的度量。某一特定词语的IDF,可以由总文件数目除以包含该词语的文件的数目,再将得到的商取对数得到:
其中
|D|:语料库中的文件总数。
j:包含词语的文件数目。如果该词语不在语料库中,就会导致分母为零,因此一般情况下使用1+j作为分母
TF-IDF = TF *IDF
2.代码的实现
使用朴素贝叶斯分类模块
最常用的文本分类方法有KNN最近邻算法、朴素贝叶斯算法和支持向量机算法。一般来说,KNN最近邻算法的原理最简单,分类精度尚可,但速度最慢,朴素贝叶斯算法对于短文文本分类效果最好,精度最高;支持向量机算法的优势是支持线性不可分的情况,精度上取中。
测试集随机抽取子训练集中的文档集合,每个分类取10个文档,过滤掉1KB以下的文档。
训练步骤与训练集相同,首先是分词,之后生成文件词向量文件,直至生成词向量模型。不同的是,在训练词向量模型时,需要加载训练集词袋,将测试集产生的词向量映射到训练集词袋的词典中,生成向量空间模型。
执行朴素贝叶斯训练:
输出结果:
输出结果:
分类结果评估
(1)召回率(Recall Rate,也叫查全率):是检索出相关文档数和文档库中所有相关文档的比率,衡量的是检索系统的查全率
召回率(Recall) = 系统检索到的相关文件/系统所有相关的文件的总数
(2)准确率(Precision,也成称为精度):是检索出的相关文档数与检索出的文档总数的比率,衡量的是检索系统的查准率。
准确率(Precision) = 系统检索到的相关文件/系统所有检索到的文档总数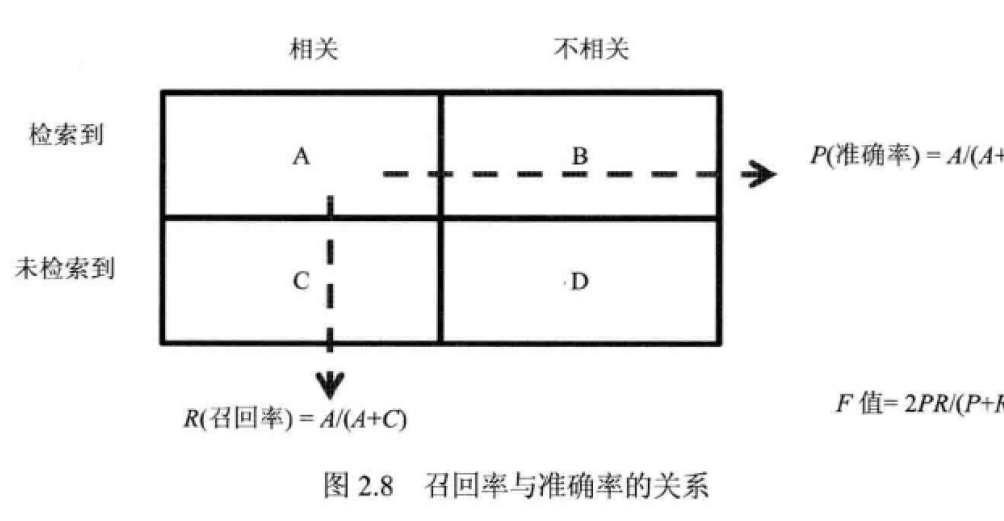
(3)Fβ-Mesure(又称为F-Score):是机器学习领域常用的评价标准,计算公式: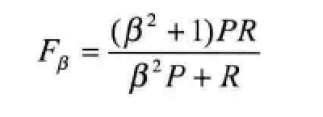
其中,β是参数,p是准确率,R是召回率
当β=1时,就是最常见的F1-Mesure了: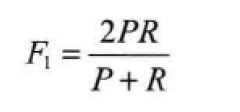
文本分类结果评估,代码如下:
输出结果如下:
精度:0.881
召回:0.862
f1-score:0.860
参考资料:《机器学习算法原理与编程实践》 郑捷