最近女朋友在背单词,加的群每天会发单词计划,是一个每日单词表,如下图所示: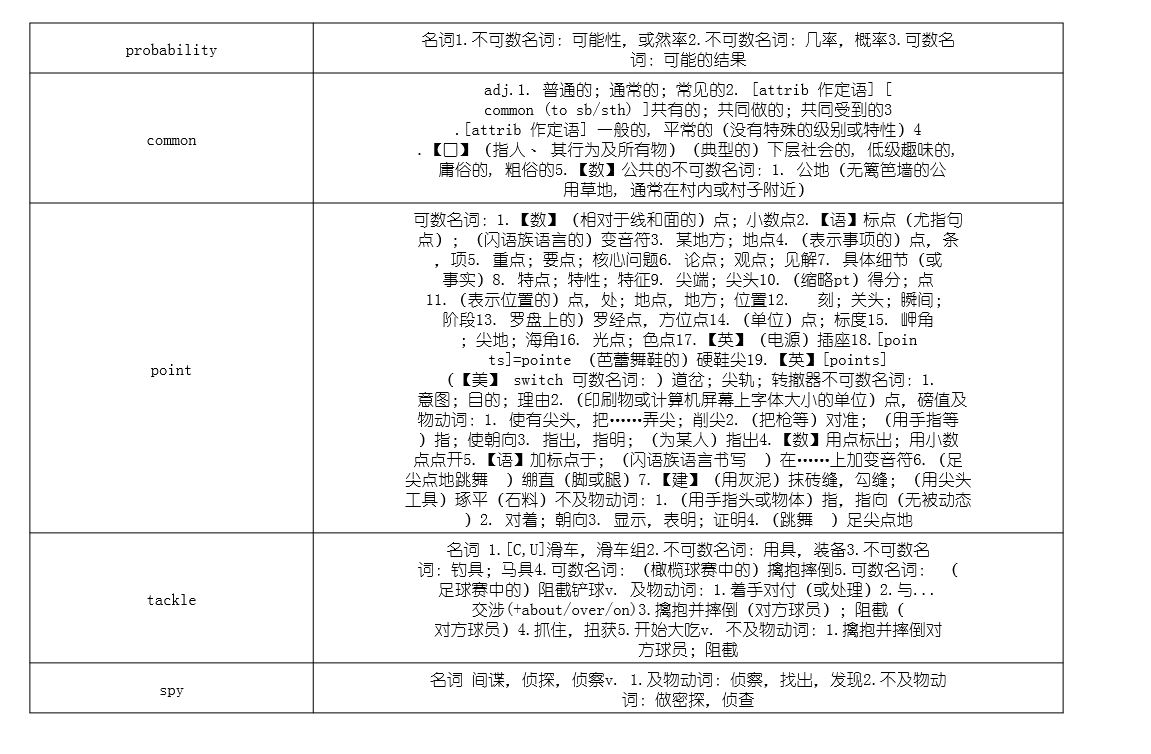
但是群里只给了五天,作为一个程序员男朋友,马上就想到了用自动化技术生成每日单词表。
需求
由于是给女朋友用的,当然不能用控制台的小黑框了。python有很多图形库,我选了一个比较简单的tkinter。
现在分析一下,我们的需求:
- 可以输入今天背多少个单词
- 可以输入今天是第几天,作为生成的pdf的名字
- 每天随机生成单词
- 背过的单词就不再使用了
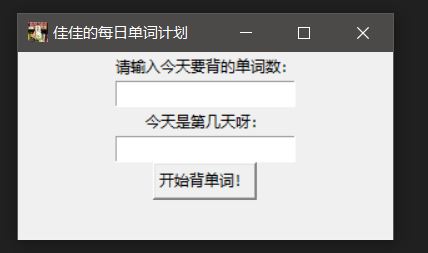
界面设计
界面很简单,只需要:
- 输入单词数量的输入框和提示文字
- 输入天数的地方和提示文字
- 提交按钮
- 显示结果
|
|
爬取词库
词库不太好找,所以我们可以使用爬虫爬取,任务比较简单,就没有使用scrapy了:
简单的小爬虫,都是比较基础的东西。
生成单词表
接下来就是根据词库来随机生成单词了:
我们要先读取词库和已背单词记录,然后随机挑出输入数量的没背过的单词。由于有的单词解释过长,所以每35个字符我们加个换行,方便我们后面生成pdf时,表格行高比较好设置。
生成pdf
接下来就是将单词表写进pdf里了。我们用到reportlab这个包:
由于我们要用到中文,所以需要先引入字体。简单点的话,字体文件就用windows自带的。表格的格式设置语法比较复杂,如果需要很复杂的表格,可以去reportlab官网找手册。默认表格行高是自适应的,所以我们上面一步加入换行符就可以让解释比较长的单词的行高更高一点,这样表格更加美观。
界面美化
设置下界面大小、偏移量和图标:
打包成exe
让女朋友用,当然不能让她再装个python用啦,所以要打包成exe。用pyinstaller打包即可。需要注意的是,pyinstaller打包时会一并打包很多不必要的模块,所以会比较大,动辄几百MB。我们用anaconda再创建一个新的python环境即可。打包的时候注意要用新的这个环境去打包。我的打包完就只有10MB了。
-F是打包成一个文件,可以试试去掉,会出现一个文件夹,里面有很多dll等。
-w是不要界面。因为我们自己写了界面了,如果不加w的话,运行时会弹出一个控制台。
打包完成后可以运行测试一下,如果一个黑屏一闪而过,可以用cmd运行这个程序,cmd里面会有报错。
不足
由于时间仓促,技术有限,这个小程序还有很多不足:
- 界面设计太简陋,可以用QT等重新写界面
- 没有错误处理(由于用户就一个,还可以随时指导,所以错误处理一概没写)
- 单词解释较长较复杂,比如一个单词意思太多,可以对单词解释进行处理一下
- 功能单一,仅满足了需求。